имени М. В. Ломоносова
-


 Научно-исследовательскийвычислительный центрМосковского государственногоуниверситета имени М. В. Ломоносова
Научно-исследовательскийвычислительный центрМосковского государственногоуниверситета имени М. В. Ломоносова
Краткое описание проекта
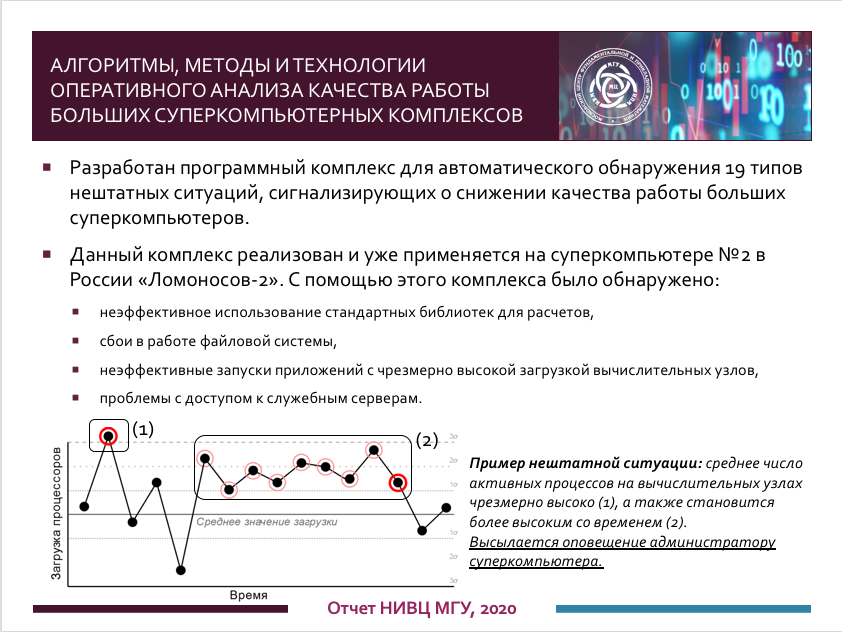
В рамках данного проекта были разработан, описан и реализован набор из 19 правил, позволяющих обнаруживать различные случаи снижения качества работы суперкомпьютера. Каждое правило задает алгоритм поиска признаков, сигнализирующих о наступлении определенного случая, содержит описание возможных причин его возникновения, а также определяет критичность возникшей ситуации. Данные правила позволяют анализировать самые разные аспекты работы суперкомпьютера: эффективность использования прикладных пакетов, работу системы очередей, загрузку и доступность служебных серверов, наличие глобальных проблем с производительностью в пользовательских приложениях, особенности использования отдельных разделов суперкомпьютера. Для этих целей выполняется анализ множества различных типов данных, получаемых с помощью систем мониторинга, менеджера ресурсов и другого системного программного обеспечения.
Разработанные правила легли в основу программного решения, которое было реализовано и апробировано на суперкомпьютере петафлопсного уровня Ломоносов-2. Данное решение постоянно работает на суперкомпьютере и с заданной периодичностью проверяет его состояние, оперативно оповещая администраторов о выявленных случаях снижения качества работы. Проведенная апробация показала применимость и полезность полученного решения на практике. Так, с помощью данного решения было обнаружено аномально неэффективное использование прикладного пакета в одном из разделов, зафиксированы признаки нештатной ситуации в работе инфраструктуры суперкомпьютера, а также найдены запуски приложений с чрезмерно высокой загрузкой вычислительных узлов, что приводило к появлению существенных накладных расходов. Данное решение разработано по возможности максимально переносимым – реализация созданных правил, а также существенная часть всей программной реализации является машинно-независимой и может применяться в других суперкомпьютерных центрах.
Перечень публикаций, подготовленных при поддержке проекта (2020 г.):
- (Q2 Scopus) Afanasyev I. V., Voevodin V. V. Developing efficient implementations of connected component algorithms for nec sx-aurora tsubasa // Lobachevskii Journal of Mathematics, том 41, №8, с. 1417–1426. DOI:10.1134/S1995080220080028.
- (Q2 WoS, принята) Afanasyev I., Voevodin V., Komatsu K., Kobayashi H. VGL: a high-performance graph processing framework for the NEC SX-Aurora TSUBASA vector architecture // Journal of Supercomputing.
- Афанасьев И. В. Разработка прототипа высокопроизводительного графового фреймворка для векторной архитектуры nec sx–aurora tsubasa // Вычислительные методы и программирование: Новые вычислительные технологии, том 21, с. 290–305. DOI: 10.26089/NumMet.v21r325.
- (принята) Afanasyev I. V., Dmitry I. Lichmanov. Developing efficient implementation of label propagation algorithm for modern NVIDIA GPUs. // Communications in Computer and Information Science.
- (Q2 Scopus) Nikitenko D. A., Shvets P. A., Voevodin V. V. Why do users need to take care of their hpc applications efficiency? // Lobachevskii Journal of Mathematics, том 41, №8, с. 1521–1532. DOI: 10.1134/s1995080220080132.
- (Q2 Scopus, принята) Shvets P. A., Voevodin V. V. "Endless" Workload Analysis of Large-scale Supercomputers // Lobachevskii Journal of Mathematics, том 42, №1.
Годы проекта2020Руководитель проектаВоеводин Вадим Владимирович
Новости
 Поздравляем с успешной защитой кандидатской диссертации Шайхисламова Д.И.10 марта 2026 14:09
Поздравляем с успешной защитой кандидатской диссертации Шайхисламова Д.И.10 марта 2026 14:09 Заседание учёного совета НИВЦ МГУ, 19 марта 2026 г.09 марта 2026 13:17
Заседание учёного совета НИВЦ МГУ, 19 марта 2026 г.09 марта 2026 13:17 "Ломоносовские чтения", 26 марта 2026 г.10 февраля 2026 15:26Б.В. Доброву присвоено звание «Заслуженный научный сотрудник Московского университета»09 февраля 2026 17:09
"Ломоносовские чтения", 26 марта 2026 г.10 февраля 2026 15:26Б.В. Доброву присвоено звание «Заслуженный научный сотрудник Московского университета»09 февраля 2026 17:09Журнал НИВЦ
